



Industrial Engineering #2 - Shiv Trisal, Databricks
Guest: Shiv Trisal | Global Manufacturing, Transportation & Energy GTM at Databricks

As industrial operators explore ways to adopt new AI-powered solutions into their modern workflows, the efficacy of their projects is closely tied to one key component: their underlying data. For customers looking to adopt best data practices, Databricks is one of the first companies to come to mind. Since its inception in 2013 by the creators of Apache Spark, DeltaLake, and MLflow, Databricks has grown into a global platform, most recently valued at $43 billion after a $500 million Series I fundraise in late 2023. To learn more about how the platform is leveraged across the industrial categories, I reached out to Shiv Trisal, who leads global GTM for manufacturing, transportation, and energy customers at Databricks. Below is an edited transcript of our discussion covering everything from the benefits of open source, the importance of Databricks’ partners, and the type of AI systems Shiv is most excited about today.
If you are building, operating, or investing in these categories, please reach out. My email is ananya@schematicventures.com – I’d love to connect!
Shiv Trisal is responsible for worldwide adoption of Databricks in the manufacturing, transportation & energy sectors and manages the development of new industry solutions, ecosystem partnerships and GTM programs that bring differentiated value to CxO priorities. Shiv has a proven track record of leading diverse teams and delivering game-changing data and AI-led innovation across Manufacturing, Transportation & Energy sectors, with roles at EY, Strategy&, and Raytheon Technologies. He regularly connects with senior executives to unfold data and AI strategies and unlock competitive advantage in their businesses. Shiv holds a Bachelor’s degree in Electronics Engineering from the Thapar Institute of Engineering and Technology in Punjab, India and a Master’s in Business Administration from the Wharton School at the University of Pennsylvania, majoring in Strategic Management and Innovation.
Can you please share a brief overview of Databricks and the key aspects of the platform that industrial operators should be familiar with?
Industrial companies can choose between general intelligence from the internet or specific intelligence derived from their operational technology and enterprise data, known as Data Intelligence. Databricks supports over 12,000 customers (ranging from Fortune 500 companies to unicorn startups) in leveraging their unique data for AI initiatives, addressing the fragmentation caused by various data sources and proprietary formats.
I spend a lot of time with industrial customers globally and stress the importance of controlling their destiny for data and AI. The industry is all about unstructured, streaming data from physical assets surrounded by complex processes that are operated for long periods of time (often decades). When I ask them where the data that powers their digital twins or AI initiatives comes from and who controls it, I get a variety of responses: “we have historians, IIoT platforms, time series databases, engineering tools, etc.”. The industry has had starts and stops with AI because of proprietary formats and specialized tools that hampered customers’ ability to take advantage of their first-party data emanating from their assets, operations, and customers.
“The Databricks platform bridges industrial and enterprise data through open standards like Delta Lake, interoperability with Delta Sharing, and governance via Unity Catalog, enabling companies to maintain control over their data, which is crucial for digital transformation. This is what makes Databricks one of the most important AI orchestrators on the planet.”
When companies develop AI or generative AI capabilities, they need a foundational data platform and a set of capabilities to help build and produce that functionality – this is our role in the industry.
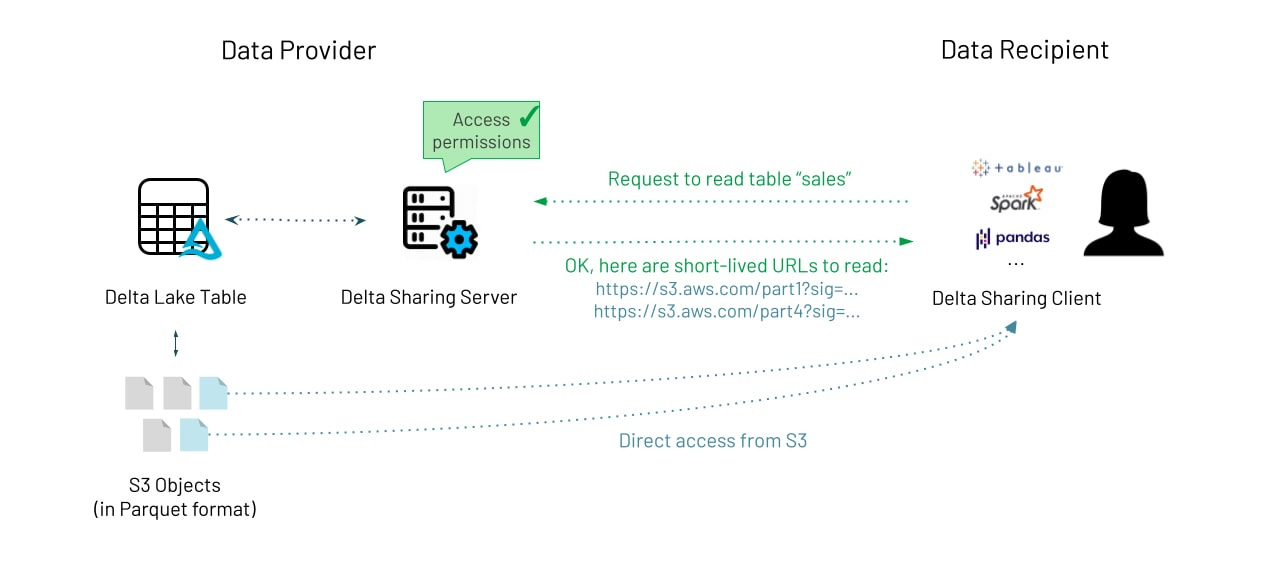
Which Databricks features have you found to be the most impactful for your industrial customers, and why?
Databricks treats all data uniformly, whether from enterprise applications, IoT sensors, or 2D/3D product replicas, simplifying decision-making for business users. For AI to take shape in this sector, we believe that industrial time series data must become a first-party citizen in enterprise AI. Databricks' focus on interoperability through open standards sets it apart in the competitive landscape. The most recent example of this is our decision to open source Unity Catalog – which can provide a unified single source of truth for data assets regardless of data type (structured, semi-structured or unstructured) – and provide a comprehensive foundation for AI development that aligns with Unified Namespace (UNS) architecture for Industry 4.0 applications.
From an ecosystem perspective, we have very successful partnerships with organizations like AVEVA, Litmus, Seeq, and Sight Machine, to help bring in high-quality OT data sets into Databricks, build AI systems on top of it, and then send intelligence back to these users to drive better decision making. We have also made cloud-native industrial time series data processing more accessible to customers with Real Time Data Ingestion Platform (RTDIP), a highly successful open-source project developed in collaboration with Shell, that now has over 135K monthly downloads. This enables companies to unleash AI and Generative AI use cases across every corner of the industry such as reducing unscheduled downtime, maintenance schedule optimization, dynamic production scheduling, power grid balancing, energy use optimization and pharmaceutical quality control, amongst others.
What is the typical profile of an industrial customer for Databricks?
It varies. About 4-5 years ago, some of the more mature technical companies would use Databricks with the mindset that after they reached a certain level of cloud maturity, they could apply Databricks because now the problem they were solving was scaling. Now with the advent of generative AI, people realize none of the AI solutions, or generative AI specifically, will work if customers have bad data training their models. It's garbage in, garbage out.
As our product capabilities have broadened and matured, people want to have a Databricks-centric approach on day one so they don't have to reinvent the wheel and regardless of where they store their data, they can have the same experience. This is what Databricks enables across different cloud platforms. From our perspective, there is no real barrier to entry at this point with Databricks and there is no lock-in because your data is always in an open format, and you control it at all times.
What is the process for prospective customers to get started with Databricks?
We have field teams in virtually every major market in the world working with customers to define what business problems they want to solve with data, analytics, and AI. From there, it’s more about delivering an end-to-end solution with an architecture that can scale across their assets, business units, and locations.
As a result of having delivered AI at scale for thousands of customers, we know the repeatable patterns and foundational architectures needed to deliver predictive maintenance, inventory optimization, or predictive quality control use cases. We codify this in our jumpstart packages and solution accelerators that companies can leverage, allowing customers to bypass lengthy discovery processes and quickly deliver business value within weeks. We've seen customers deliver value with their initial use case ideas in two weeks and then launch in production a few weeks after, often working with our ecosystem partners to accelerate the customer’s journey.
What is one trend in the data infrastructure space you are following right now?
I think the most exciting trend is the shift towards compound AI systems that outperform systems that rely heavily on individual models. Think about it: deploying a predictive maintenance capability is not just about deploying a one-time series prediction model. Typically, it begins with telemetry/sensor data from equipment being continually analyzed for anomalies and aggregation into an asset health score. It requires predictive modeling to estimate RUL (Remaining Useful Life) for critical systems and an autonomous agent to create work orders in the maintenance scheduling system. From there, field technicians would use LLMs to interact with technical manuals, knowledge bases, and warranty statuses to receive more prescriptive information on the most effective action to maximize uptime and empower field staff to be more productive.
“A systems approach that harnesses the strengths of various components provides the right foundation to build higher-quality domain and task-specific applications, which will ultimately drive higher ROI for the end customers.”
Is there any advice you would share with startups building data solutions for the industrial category?
Companies don't usually have an AI strategy; they have a business strategy. Early-stage companies should focus on the very, very specific problem they're trying to solve through AI and the value that it brings. They should be speaking in the business language, not in the AI language; this is critical and something we had to do at Databricks ourselves. Many of our sales and product team members are deeply technical as they can go into the depths of AI, data engineering, and related disciplines. But if you're trying to sell to a business executive, the only three things they care about are 1. how does this help them reduce cost, 2. how does this help them increase revenue or take products to market faster, and 3. how does this help them manage risk from a compliance perspective.
This is softer advice but is very important because it can make or break your company if you're unable to communicate the value you bring. At the same time, you have to think about how your solution fits into the broader strategy of the company from a data or AI perspective. This is going to be critical – don’t underestimate it.
There are going to be some point solutions that companies can buy every now and then but if things don't fit with their architecture and their road map as a company and how they want to incorporate AI into their business, it's going to be challenging. My advice would be to not underestimate the importance of plugging into the broader technology platforms that these companies are investing in to shape their AI strategy.
Any final words or key takeaways for readers?
As you start building out your own AI capabilities, think about the impact of open technologies and how your products integrate with that because that's the direction we see companies moving towards, more and more. Meta just announced Llama 3.1 and you can see the advantages that open source technology brings; your ability to integrate well with it can define your success or failure in the long run.
If you’re interested in learning more about the solutions that Databricks offers for manufacturing and other industrial applications, you can find more information and connect with the team here.
---
This series focuses on navigating technical software decisions within industrial companies. From optimizing infrastructure choices and leveraging DevOps best practices to harnessing the power of cloud technologies and improving data workflows, our guests will highlight how they've considered these decisions and implemented new solutions across their organization. If you're similarly excited about leveraging technology to empower our national industrial base and/or building solutions focused on this category, please reach out!