


To understand how we get to the point of robot dogs balancing on bouncy balls or humanoids playing soccer, we start with data.
What are the different types of data?
There are two primary methods robotics companies (either those building foundation models for generalized physical intelligence or those developing end-to-end applications with integrated hardware) leverage for their data inputs: real or synthetic.
Real-World Data: This entails captured image and video footage of target actions occurring in real life, and is often considered the holy grail for training data. For example, Waymo released a portion of their driving database, sharing thousands of sensor, mapping, and imagery data of on-the-road conditions, and the LeRobot community on HuggingFace offers a range of datasets for common actions such as sorting and stacking.
Companies looking to use real-world data can rely on publicly available sources (such as those mentioned above), their own proprietary data (collecting the necessary information through real-world interactions), or using third-party systems to collect the data on their behalf. Startups like DXTR and Roughneck provide data collection platforms where robotics companies can request and structure their real-world data collection practices.
Synthetic Data: Synthetic data are artificial datapoints that have been generated to simulate real-world data. For example, if a company is training a model to understand food preferences and provide restaurant and recipe recommendations based on user preferences, it could create a dataset based on the specific data needs they are seeking, such as:
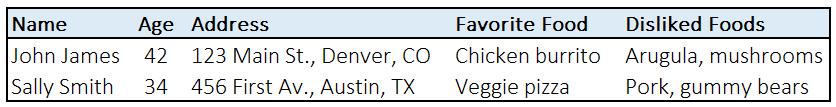
By using a synthetic dataset, companies can leverage far more data when training their models, often at lower costs than collecting real-world data. However, synthetic data may include biases or inconsistencies not present in real-world data, so it is vital to keep in mind when training models. Companies aiming to use synthetic data can leverage tools like NVIDIA’s physical AI synthetic dataset or Synthetic Data Generation platform. Startups like AuraML and Kyral, and academic projects like Synthetica, support the creation of synthetic datasets for a wide range of use cases.
As Nicholas Radich, co-founder of Roughneck, shared:
“What powered breakthroughs in vision and language wasn’t just smarter models, it was access to the right datasets. Robotics has no equivalent foundation yet, which is why embodied data infrastructure is so critical.”
How is the data collected?
Real-world data for robotics training and development is collected through a wide range of sources, from cameras to LiDAR to torque sensors and actuator feedback. Depending on the use case, environmental data such as factory floor layouts or terrain models can help with navigation, and CAD models and internal knowledge bases can help with action planning and execution. For example, if you’re trying to collect visual data within a large unstructured environment (such as a construction site, warehouse, or manufacturing facility), Boston Dynamics offers a tutorial on leveraging Spot and simple webcams to autonomously collect data. Furthermore, the HARPER dataset is a unique lens into potential interactions between a human and Spot robot, anticipating avoidance routes in case of any potential crashes, using motion capture cameras in both RGB and greyscale, as well as depth sensors, to generate skeletal representations with sub-millimeter precision.
When researchers and developers are defining their data collection process, they often include a few key specifications around the types of data they are hoping to collect, including the category, quantity, and task diversity. More specifically, datasets can include information from video cameras (either RGB or greyscale); LiDAR, RADAR, and other depth perception sensors; audio recorders; or infrared and multispectral cameras. Depending on the use case and type of robot being trained, developers may select between area or line scan cameras, which can capture the movement of an object over time (such as atop a conveyor belt), or rolling or global shutter cameras, which can capture real-time pictures of fast-moving objects with minimal distortion. Although a simple rule of thumb may be that more data is better in terms of capturing potential edge cases and a variety of conditions (such as the impact of fog or rain, or shadows depending on light during various times of the day), thoughtfully planning for different scenarios and tasks (such as a pedestrian running into the road or an unexpected falling object for autonomous driving use cases, or a human colliding with a warehouse robot) is also important.
As Ken Goldberg, co-founder of Ambi Robotics and Jacobi Robotics, and Distinguished Professor at UC Berkeley, shared in a talk, “Using commonly accepted metrics for converting word and image tokens into time, the amount of internet-scale data used to train contemporary large vision language models (VLMs) is on the order of 100,000 years.” Closing the data gap in robotics may take many more years, so new approaches leveraging reinforcement learning and fine-tuning are helping speed up the commercialization process.
When researching more about real-world data collection, I enjoyed reading this paper on Robot Utility Models. In particular, the authors redesigned a handheld device with a mounted smartphone to capture data. I was interested in learning more about the process, time, and cost of collecting real-world data so I decided to try building my own dataset. Further notes on that process and my learnings from the experience are shared here.

Synthetic data can be generated in simulated environments or by modifying real-world data. AI and statistical modeling are hugely beneficial in supporting synthetic data generation, especially with tools such as BigQuery DataFrames and AWS SageMaker Ground Truth, and startups such as Gretel (acquired by NVIDIA), YData, SceniX, and Parallax Worlds to generate and test synthetic data in high-fidelity simulated environments.
One of the key considerations for companies leveraging synthetic data is that using large quantities of such data can exacerbate the sim2real gap, which occurs when there are unexpected performance differences in the model when deployed in real-world environments if the model was trained primarily on synthetic data earlier. Synthetic or simulated data can emphasize certain biases and patterns that may not be fully aligned with real-world probabilities or environments, so model performance can be impacted as it may have been over-fit to the training data and then fails to generalize. To determine the accuracy of a model, researchers calculate the loss function, measuring the difference between the predicted output from the model and the real-world event. Additionally, the high degree of complexity and associated costs in generating accurate multi-physics simulations have historically made it difficult to rely entirely on synthetic environments to scale data collection.
What happens after the data is collected?
After the data is collected and stored in a safe repository, either a private cloud or public system such as Hugging Face, it must then be cleaned. This process usually requires a few steps, but typically includes removing any unusable data (such as a video with no visibility from a camera sensor due to fog or such loud background noise that an audio input is not feasible). Then, the data must be annotated so the model can effectively learn what an ideal environment and successful action look like. Data labelling companies such as Scale and Surge AI focus specifically on data quality, providing access and annotations for a wide range of data types. Once the data is cleaned and processed, it is ready to be input into the model as it begins the training process, the subject of my next article in this series.
What are the key considerations for founders in this category?
To better understand how founders evaluate tradeoffs in data and where they see the market heading, I reached out to Ayush Sharma, CEO of AuraML. He shared his perspective on the ecosystem and areas of opportunity that exist today.

How do you evaluate the tradeoffs between real and synthetic data?
The framework we share with our customers to consider when evaluating the tradeoffs includes:
Difficulty of collecting real data: For example, if you are training your robot for a rare/hazardous situation or if you need access to proprietary information to generate the datasets, there might be no choice but to rely largely on synthetic data.
Cost of the dataset: If you need lots of data at a low cost, synthetic data might be the way to go. However, we typically recommend fine-tuning on at least 10% real data during post-training.
Accuracy of the data: Some synthetic data (such as on-the-road driving data for autonomous vehicles) is easier and more accurate to generate than other data (such as realistic humans or internal organs).
Ease of annotation: Images and videos are relatively easy to annotate, whereas other sensor data (particularly 3D lidar point clouds) might be more challenging.
What is the biggest challenge you face today for robotics data?
The two biggest challenges (both of which we are trying to solve at AuraML) are:
Generating 3D environments and scenarios: Creating accurate 3D scenes that match the real world is very challenging. You need to hire a team of 3D artists who will work for a few months and charge 5 figures just to create a simple static scene. If you want to add dynamic elements, like moving machinery or humans, that further increases the complexity. Additionally, to make any variations or changes in the environment, the 3D artists manually create those changes each time.
Multi-sensor data: Robotics requires data from different sensors like cameras, lidar, IMU, GPS, encoders, and tactile sensors. Images/videos from cameras are readily available but it can be difficult to find data from other sensor modalities.
In ten years, will we still need more robotics data? If so, how will it be collected, sorted, and stored? If not, why?
We will definitely need more robotics data as robots are just getting started. If we want to see robots in every task and environment and a truly general multipurpose robot AI brain, it will definitely take more time. As more use cases are unlocked, we will have a continuous need for data.
However, the paradigm will be completely different than today. We will have a large multi-modal world generation model running on a large GPU cluster with GW power acting as the synthetic data generator for smaller models that reside on the robots themselves with limited compute and power. The world model will have a complete understanding of the physical world and will be able to generate any scenario with multi-sensor output streams. This data will also be perfectly annotated by the large world model itself.
There will be no need for collection, sorting, or storage. The multi-modal world simulation model will generate on the fly whatever data is needed for the smaller edge robotics models to consume, train, and test. There will be AI agents that automate the entire process, and AI itself will train other robotics AI in an automated way.
The only case where we won't need data is if we have robot AGI by then that can run on small form factor compute hardware, which can fit on a robot while having a meaningful battery life (but I think this is highly unlikely in ten years).
What is one specific problem you would like to see solved regarding robotics data?
I would like to see physics-based neural networks that can generate accurate sensor data and emulate real-world physics interactions accurately while being cheaper for compute than the current classical physics solvers and expensive ray traced rendering we have today.
What is Schematic most excited about in the data category?
As we consider the data generation and ingestion process for robotics applications, we are particularly interested in backing companies with:
A Unique Moat for Real-World Data Collection: Companies with a clearly defined, long-lasting edge in collecting real-world data, either through differentiated hardware or distribution channels.
Improved Simulation for Synthetic Data Generation: Companies building high-performance simulations closely reflecting real-world environments with a wide range of variability and synthetic data capture solutions across modalities (such as audio or sensor input).
Autonomous Annotation for Large-Scale Data Sets: Today, annotation is a highly manual process given the level of variability and strict accuracy requirements for cleaning data. Companies developing methods to quickly screen and clean data will be helpful in quickly moving data from the collection phase to model training.
If you're building or investing in these categories, or are similarly excited about unearthing better data sources to train robotics systems, let's chat!